Most labeling projects do not fail at the labeling. They fail at the taxonomy: the set of categories, spans, and rules that determines what an annotator is permitted to record. A weak taxonomy performs adequately in a pilot and breaks under volume. Across a thousand clips of real homes, two annotators disagree on where a grasp ends, a third improvises a label because none of the defined ones fit, and within weeks the team is relabeling against a definition that should have been written on day one.
For manipulation video the stakes are higher than for general action recognition. The task is not tagging 'cooking' on a thirty-second clip. It is marking the frame at which a hand makes contact, the moment an object leaves the surface, the instant a pour begins to fail. These boundaries become supervision for a policy that will eventually move a physical arm. A taxonomy that is vague about them passes that vagueness directly to the model.
This is a practical guide to designing a taxonomy that holds up against production data. It is written for teams scoping a manipulation dataset, whether they label it in-house or ask us to deliver it raw or labelled. Treat the taxonomy as a first-class design decision rather than a downstream detail bolted on after capture. It is far cheaper to specify correctly at the outset than to migrate later.
Label what the hand does, not just what it touches
The default instinct is to label objects: draw a box around the mug, the kettle, the drawer, and call the clip annotated. Object detection is a well-understood problem and feels like progress. But a manipulation policy does not need to know that a mug is present. It needs to know what was done to it, in what order, and whether the action succeeded.
The backbone of a manipulation taxonomy is therefore verbs and affordances, not object classes. The unit of meaning is the action: reach, grasp, lift, transport, rotate, pour, place, release. Objects are arguments to those verbs rather than the labels themselves. 'Grasp(handle)' encodes the affordance, the fact that this is a region that can be gripped in a particular way, which is far closer to the signal a policy must learn. A bounding box on the kettle does not capture it.
This matters because affordances generalise where object identities do not. A policy that learns to grasp the graspable region of a handle-shaped object transfers to handles it has never seen; a policy that learns that the kettle sits at a fixed set of pixels learns only your kitchen. The taxonomy is where you decide which of these two things your labels encode. Datasets such as Epic-Kitchens organise their annotations around verb-noun pairs for precisely this reason: the verb is the component that travels.
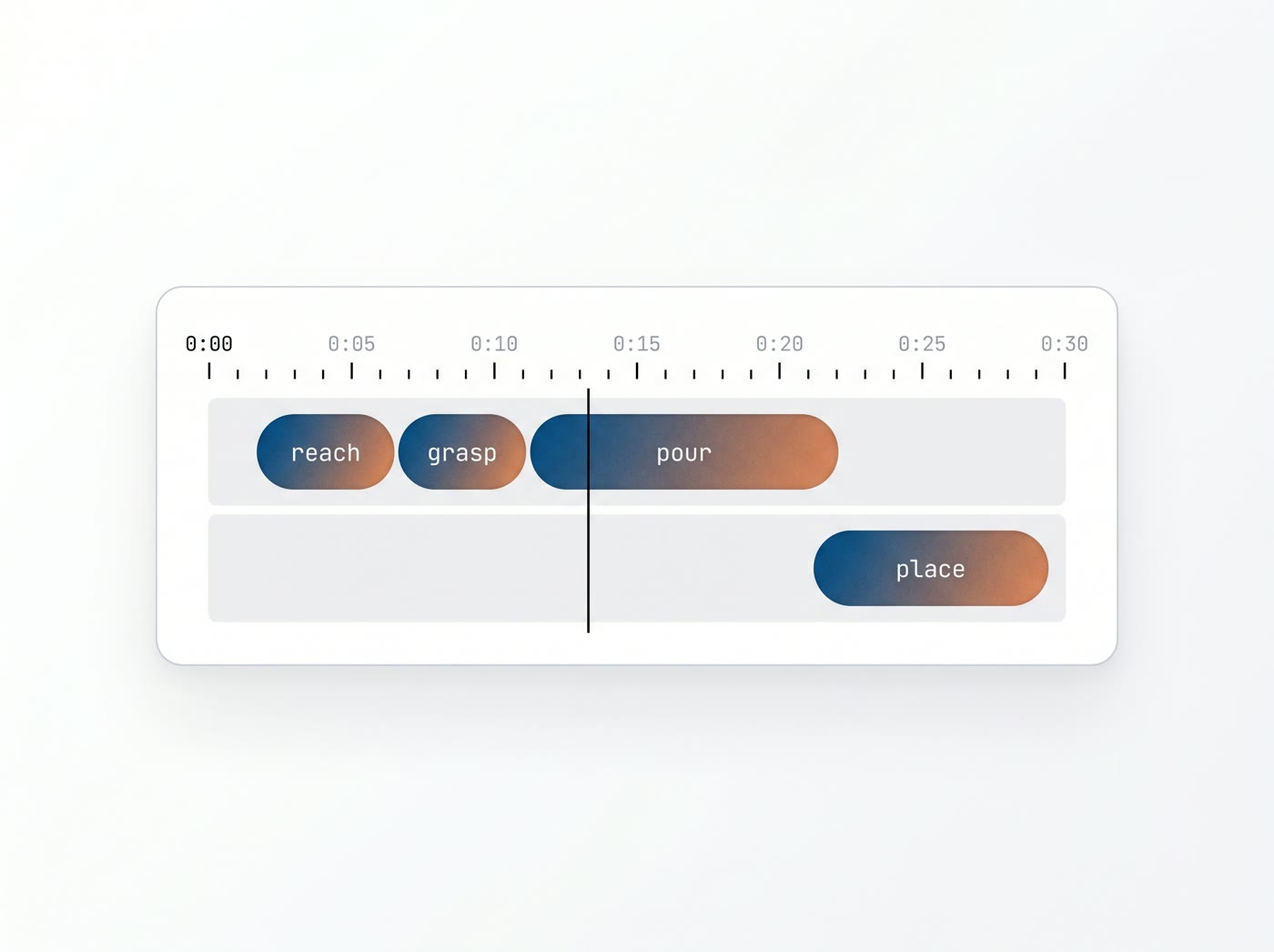
Temporal action spans and phase boundaries
A clip is rarely a single action. Picking up a mug and moving it is a sequence of phases, and the most useful labels live at the phase level. A standard decomposition for a pick-and-place is five spans, each with a defined start and end frame:
- Reach. From the onset of arm motion toward the object until the hand makes contact.
- Grasp. From first contact until the object is secured and load is taken.
- Transport. From the moment the object leaves its surface until it arrives above the target.
- Place. From the start of the lowering or positioning motion until the object rests at the target.
- Release. From the onset of finger opening until the hand has cleared the object.
Each span is a temporal segment with defined boundaries rather than a single keyframe, and this is what separates a trainable dataset from a collection of activity tags. The Something-Something dataset demonstrated how much signal resides in fine-grained, temporally precise actions rather than coarse activity labels. The distinction between 'moving something' and 'pretending to pick something up' lives almost entirely in the motion and its boundaries. For manipulation, the boundaries are the supervision: a policy learning when to close its gripper requires a precise account of when the human did.
Phase boundaries also provide what a single activity label cannot: alignment between labels and synchronised motion. When the motion is attached to the video, the grasp-onset frame is where the hand's joint angles converge into a grip. The taxonomy and the motion then agree on the same instant, and that agreement is much of what makes the data trainable rather than merely watchable.
Choosing granularity is most of the work
Granularity is the single decision that breaks the most projects. Too coarse, and you erase the signal: if 'tidy the kitchen' is one label, the model learns nothing about how to tidy. Too fine, and you destroy agreement: ask annotators to distinguish 'pre-grasp finger extension' from 'grasp approach' frame by frame, and few will draw the line in the same place. The labels become noise presented as precision.
The correct granularity is the coarsest level that still preserves the distinctions the model must make. This is a function of the downstream objective, not of how detailed the annotation could conceivably be. If the policy only needs reach-grasp-transport-place-release, do not label finger micro-phases. If it must learn re-grasp recovery, a single 'grasp' span is too coarse and should be split.
Granularity is the point at which two parties who never meet must both succeed: the annotator who has to apply a label consistently, and the model that has to learn from it. The right level is the one at which neither is asked for more than they can deliver.
Motionstack
The two-annotator pilot
A practical test resolves this directly. Before finalising the taxonomy, have two annotators label the same ten clips independently. If they agree on the spans, the granularity is survivable. If they routinely disagree by more than a few frames, or debate which label applies, the taxonomy is asking for a distinction the data does not cleanly support. Coarsen it, or write a sharper rule, before scaling to a thousand clips and baking the disagreement into the training set.
Encoding intent and failure, not just geometry
Bounding boxes and spans record what happened in space and time. They do not record why, or whether it worked. For manipulation, both are valuable, and most taxonomies omit them.
Intent is the goal behind the motion. A reach toward a mug to pick it up and a reach toward a mug to push it aside are visually similar for the first several frames yet mean entirely different things. If the taxonomy cannot express the goal, the model must infer it from pixels alone, and it will sometimes infer wrong. A light intent annotation, recording only the target object and the goal verb, disambiguates motions that are otherwise near-identical.
Failure modes are more valuable still, because failure is rare in the wild and a policy that has never observed a recovery cannot perform one. The taxonomy should carry first-class labels for what goes wrong: a slip, a missed grasp, an object knocked over, a re-grasp, an aborted reach. Mark the failure span, and mark the recovery where one exists. A dataset of clean successes teaches a policy to be confident and brittle; a dataset that labels its failures teaches it what to do when the world does not cooperate, which is much of the time.
This is also where the difference between scraped video and commissioned home data becomes decisive. Intent and failure are difficult to label reliably on edited how-to footage, where the failures are cut and the intent is narrated rather than enacted. They are straightforward to label on unedited first-person captures of ordinary people performing ordinary chores, which is the data this taxonomy is built to describe.
Boundary ambiguity, and how to define around it
Where exactly does a reach end and a grasp begin? Reasonable annotators disagree, and the disagreement is not a failing. It reflects a genuine ambiguity in continuous motion. The task of the taxonomy is not to pretend the ambiguity does not exist but to make an arbitrary yet consistent ruling and document it, so that annotators converge on the same call.
Effective boundary rules anchor to observable events rather than to judgement. 'Grasp begins at the first frame of hand-object contact' is a rule two people apply identically; 'grasp begins when the hand is about to grip' is not. Where the visual event is itself ambiguous, anchor to the synchronised motion: 'transport begins on the first frame the object's vertical position increases' is unambiguous because it is a measurement rather than an opinion. The more boundaries pinned to a measurable threshold, the higher the agreement, and the less the dataset depends on annotator intuition.
Document these rules as a labeling guide with worked examples and edge cases, and maintain it as a living document. Every genuine disagreement that surfaces during labeling is a gap in the guide. Patch the gap with a new rule and a new example, and the next thousand clips inherit the fix. The guide, not the tooling, is the real deliverable behind a clean dataset.
Inter-annotator agreement and adjudication
You cannot manage what you do not measure, and the quantity to measure here is whether annotators agree. Inter-annotator agreement is the early-warning system for a taxonomy that is beginning to wobble. Have multiple annotators label an overlapping sample, measure how often they match on label choice and how tightly their span boundaries align, and track those figures as the project scales.
When agreement is low, the taxonomy is more often at fault than the annotators. Two labels that are constantly confused should be merged or given a sharper boundary rule. A span whose boundaries scatter by half a second needs a measurable anchor. Treat low agreement as a design signal, not a training problem to be suppressed with stricter QA.
For the disagreements that remain, establish an adjudication path: a senior annotator or reviewer who resolves conflicts and, critically, feeds each resolution back into the guide. Adjudication that fixes only the one clip is wasted; adjudication that converts each conflict into a rule compounds, and agreement climbs over the life of the project rather than staying flat. That feedback loop is what large-scale annotation efforts such as Ego4D rely on to keep thousands of hours consistent across many annotators.
Aligning the taxonomy to the model objective
A taxonomy is rarely correct or incorrect in the abstract. It is correct relative to what the model is trying to learn. The same clip warrants different labels depending on the objective, and overlooking this is a common route to beautifully annotated data that trains nothing useful.
An imitation-learning policy that consumes action chunks requires dense, phase-level spans aligned to the motion stream. A high-level task planner requires coarser sub-task segments and the intent behind each. A vision-language-action model trained across many embodiments, in the manner of Open X-Embodiment, requires a consistent action vocabulary that survives translation between robots and data sources. Before writing a single label, write the sentence that states what the model will predict from these annotations. The taxonomy follows from that sentence.
This is also the cheapest moment to involve the people training the model. A thirty-minute conversation about the objective, held before capture, prevents the far more expensive version of the same conversation: the one held after delivery, when the labels do not match the loss function and the data must be reworked.

Versioning and migration
A taxonomy will change over time. You will discover a missing failure mode, split an overloaded label, or sharpen a boundary rule. The question is not whether it changes but whether the change costs a day or a month, and that is decided by whether the taxonomy was versioned from the start.
Treat the taxonomy like code. Assign it a version number, maintain a changelog, and tag every annotation with the taxonomy version under which it was produced. When you split a label, define an explicit mapping from old to new so that existing annotations migrate programmatically rather than by hand. Some changes are clean (renames, or splits with a deterministic rule) and migrate automatically. Others, such as a revised boundary definition, require re-review of the affected spans. Knowing which is which, before changing anything, is the difference between a migration and a redo.
The discipline pays off most when datasets are merged. The moment you combine your labels with an external set, or deliver to a customer with their own schema, the version tag and the mapping table are what allow reconciliation without guesswork. A taxonomy with no version is a taxonomy you can use only once.
Common pitfalls
Most taxonomy failures are variations on a short list. When scoping a labeling effort, check the design against these before scaling:
- Labeling objects instead of actions. Boxes on the mug tell a policy what is present, not what to do. Lead with verbs and affordances.
- Activity tags instead of phase spans. 'Cooking' on a whole clip discards the boundaries that constitute most of the supervision.
- Granularity chosen by ambition rather than objective. Too fine destroys agreement; too coarse erases signal. Choose the coarsest level that preserves the distinctions the model needs.
- Boundaries defined by judgement. 'About to grasp' cannot be applied consistently. Anchor every boundary to an observable or measurable event.
- Only labeling successes. A dataset with no failures teaches a brittle policy. Make failure and recovery first-class labels.
- No labeling guide, or a dead one. If disagreements do not become new rules, agreement does not improve.
- No version, no migration plan. An unversioned taxonomy cannot be evolved without a full relabel.
- Building the taxonomy after capture. By then the framing, the modalities, and the objective are fixed. Decide the taxonomy first.
The taxonomy is a decision, not a detail
It is tempting to treat labeling as the routine work that follows the more interesting work of capture. In manipulation the relationship is inverted. The taxonomy determines whether thousands of hours of real, diverse, consented video become trainable supervision or an expensive archive of clips no one can learn from. It is the contract between the data and the model, and like any contract it is far cheaper to negotiate at the outset than to renegotiate after delivery.
For that reason we treat the taxonomy as a first-class decision rather than a delivery afterthought. We can supply raw captures for your own pipeline, or deliver them labelled against a taxonomy designed around your model's objective: versioned, boundary-defined, agreement-measured, and built to survive the migration you will eventually want. Pricing scales with capture and labeling scope, which you can scope on the pricing page.
If you are commissioning manipulation data and the labels matter, tell us the objective first. We will design the taxonomy around what the model has to predict, prove the granularity on a pilot, and deliver labels that hold up as the dataset grows.