Every dataset we ship can leave the building in one of two states. Raw means the footage plus its frame-aligned motion, as delivered, with no human judgement layered on top. Labelled means the same footage and motion accompanied by a structured layer of annotations that tells a training pipeline what is happening, when, and why. The capture is identical in both cases. What differs is whether someone has already converted the recording into supervision.
Many teams treat labelled as the superior product. The footage has been paid for, so annotating it feels like the natural next step, and annotated data presents as a more finished artifact. That assumption deserves scrutiny, because it misleads in ways that compound. Labelled is not categorically better than raw; it is a tradeoff, and which side serves a given team depends on where its model sits in the development lifecycle.
This article sets out a framework for that decision: when raw is the correct deliverable, when labels earn their cost, what a good label actually encodes, and why committing to a taxonomy prematurely is among the more expensive errors in the pipeline.
What raw and labelled actually mean here
Raw is not unprocessed. The video is calibrated, the motion is synced frame to frame, the rig is consistent, and the rights are cleared. What raw lacks is interpretation: no one has yet decided that frames 0 to 240 are 'approach', that frames 241 to 600 are 'grasp', or that the contributor's first attempt was a failure. Raw is the complete physical record with the semantics deliberately left open.
Labelled supplies that interpretation. At minimum it segments the footage into named, frame-aligned spans and attaches a vocabulary to them. The annotations are derived data: they sit on top of the raw, they encode choices a human or model made, and they can be redone. The footage is the asset. The labels are one reading of it, and another can always be commissioned.
Holding that distinction firm accounts for most of what matters. Capture and labelling are two separate jobs, and we price them separately for exactly that reason: a team can take the raw and annotate it in-house, route it to its own labelling provider, or have us do it. Buying footage does not commit a buyer to a single reading of it.
When raw is the right deliverable
Raw is the correct deliverable more often than teams expect, and it is the stronger fit in the early and exploratory phases of a model's life. Four situations favour it.
Pretraining and self-supervised objectives
A model being pretrained as a representation or world model consumes no labels. Self-supervised objectives learn structure from the data itself: predicting future frames, reconstructing masked patches, contrasting clips, modelling the dynamics between observation and motion. Their central advantage is that they scale on unlabelled data, which is part of why Ego4D was constructed as a large reservoir of first-person activity rather than a curated labelled benchmark. Annotating footage destined only for a self-supervised loss means paying to produce a column the training run never reads.
An unsettled taxonomy
Labels encode a vocabulary, and that vocabulary is a commitment. Where it remains undecided whether 'open drawer' and 'open cabinet' are one action or two, or how finely a pour should be split into reach, tilt, and recover, any labels commissioned now amount to a guess. When the guess changes, as it routinely does early on, the labels are stranded against a vocabulary that is no longer in use. Raw footage avoids this exposure because it has committed to nothing.
Flexibility and the avoidance of rework
Raw is reusable across objectives, model architectures, and label schemes that do not yet exist. A single clip of someone loading a dishwasher can serve a pretraining run this quarter, a grasp-detection head next quarter, and a long-horizon planning model after that, each with a distinct annotation layer derived on demand. Locking the footage into one label scheme early narrows what it can later become.
- Pretraining or self-supervision. The objective learns from the data itself, so labels add cost without adding signal.
- Unsettled taxonomy. The action vocabulary is still moving, so a label purchased now is a guess that may have to be redone.
- Maximum reuse. One raw corpus can back many models and many label schemes derived later, on demand.
- Speed to a corpus. Capture is the long-lead step; getting footage flowing while the semantics are decided in parallel shortens time to a usable dataset.
The throughline: capture carries the real-world lead time, governed by people, places, rigs, and consent. Annotation is comparatively fast and can be performed later, against a vocabulary that has actually been validated. Getting raw footage flowing first, then settling the labels in parallel, is the faster path to a usable corpus rather than the slower one.
Footage is the durable asset; a label is one reading of it. The world can be captured once and annotated repeatedly, in as many schemes as successive models require.
Motionstack
When labelled earns its cost
Labels earn their cost the moment a training step consumes them, and that moment is concrete. Once the taxonomy has stabilised and a supervised model is in training, good labels are signal rather than overhead.
Fine-tuning a specific capability
Moving from a general representation to a policy that must perform one thing reliably requires supervision targeting precisely that thing. Fine-tuning a manipulation head on frame-aligned action spans gives the model the exact boundaries it requires: where the grasp starts, where the place ends, which segment is the relevant one. This is the regime that datasets such as BridgeData V2 are built for, where labelled demonstrations are the point rather than a layer added later.
Evaluation and supervised heads
What has not been labelled cannot be measured rigorously. An honest evaluation set requires ground truth: the correct action span, the correct phase boundary, the verdict on whether an attempt succeeded. The cross-embodiment policies pooled in Open X-Embodiment and the action models in RT-1 depend on labelled spans to train supervised heads and to score them. Any reported number rests on something that was labelled; the operative question is whether it was labelled deliberately or inferred from a noisier proxy.
The pattern is consistent: labels are worth paying for when a loss or a metric reads them. Before that point they are speculative inventory. After it they are often the most valuable contents of the dataset.
What a good label actually encodes
This is widely underestimated, so precision is warranted. The bounding box is among the least informative labels in this domain. A bounding box locates the kettle. It says little about behaviour, and behaviour is the principal target of a manipulation policy. The labels that move a policy concern structure over time and intent, not object location in a single frame.
A label layer worth commissioning encodes what is genuinely hard to recover from raw pixels:
- Task phases. The coarse arc of an activity (approach, contact, manipulate, release) segmented with frame-accurate boundaries.
- Action spans. The fine-grained, frame-aligned start and end of each named action, so a supervised head learns where a behaviour begins and ends rather than inferring it.
- Intent. What the contributor was trying to achieve, which disambiguates motions that look identical but mean different things (reaching to grasp versus reaching to steady).
- Failure modes. The attempts that went wrong, and how: a dropped object, a missed grasp, a recovery. Negative and corrective examples are among the highest-value frames in the set, and they are invisible to a labeller who marks only successes.
None of these are readable from a single frame. Each requires watching the clip, understanding the activity, and exercising judgement, which is why a good annotation layer is worth paying for and why a premature one is costly to discard. We treat the construction of one at length in our note on action labelling and taxonomy.
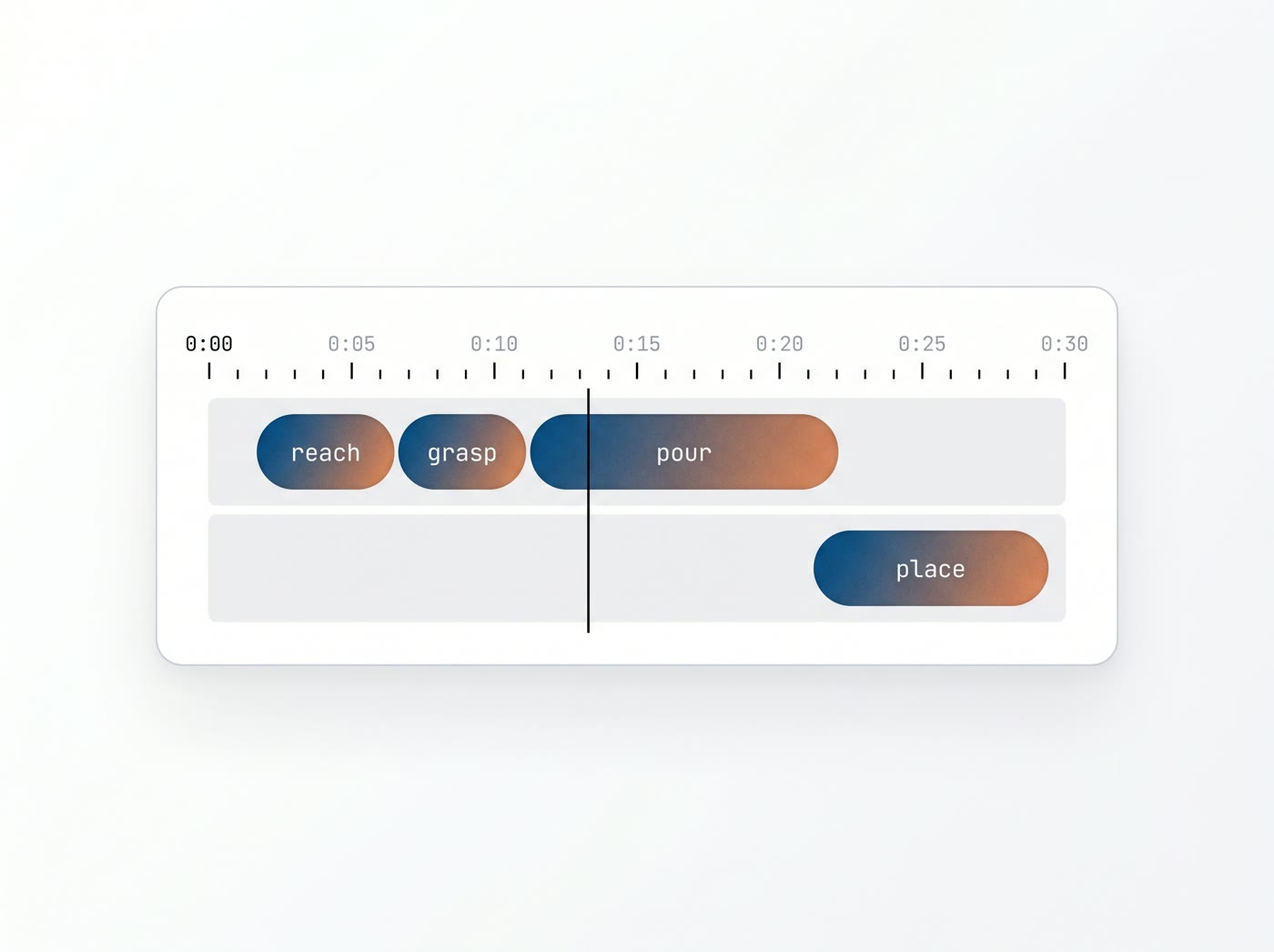
The cost and rework risk of premature labels
An asymmetry shapes this decision. Annotation is human work, priced per clip and per pass, and a behaviour-level label costs considerably more than a bounding box because it requires watching and judging rather than drawing a rectangle. That cost is well spent when the labels are used. It is wasted when they are not.
Premature labels do not sit harmlessly until needed; they go stale. The moment one action is split into two, two phases are merged, or failure acquires its own sub-taxonomy, every label tied to the old vocabulary is stranded. The options are to re-annotate from scratch, which means paying twice, or to keep training against a scheme the model has outgrown, which caps how good the policy becomes. The footage is unaffected: it never committed to the old vocabulary, so it is ready for the new one the moment it is defined.
This is why raw is the safer default early. A premature label behaves like a liability that depreciates. Raw footage behaves like an asset that holds its value.
A reliable pattern: pilot raw, then commission labels
Teams that handle this well converge on a common sequence. It is less a compromise between raw and labelled than a discipline for applying each where it belongs.
- Pilot in raw. Capture a representative slice of the task as raw footage plus synced motion. Use it for pretraining and, equally, to learn what the action vocabulary actually needs to be.
- Settle the taxonomy. Let real footage indicate where the boundaries fall, which actions are distinct, which phases matter, and how failure is defined. Validate the scheme on a small hand-labelled batch before scaling it.
- Commission labels at production volume. Once the vocabulary is stable, annotate the full corpus against it (frame-aligned spans, phases, intent, failure modes) with confidence that the labels will be consumed and are unlikely to be stranded.
This sequence inverts the costlier default. Rather than guessing a taxonomy, paying to label against the guess, and paying again when the guess changes, comparatively cheap raw footage de-risks the more expensive labelling. By the time behaviour-level annotation is purchased at scale, it is annotation with good reason to be used. The mechanics of how we run capture are set out in how it works, and how consent and rights stay clean across both raw and labelled deliverables on our trust page.
The decision remains yours
Because capture and labelling are genuinely decoupled, the choice stays open at every step. Take the raw and annotate it in-house. Route it to a labelling provider already trusted. Or have us deliver it training-ready against a validated taxonomy. None of these paths is foreclosed by the others, and none alters the underlying footage. The asset is the same world, captured once; the decision is when, and by whom, it receives a reading.
Where a corpus is being scoped and the required state is unclear, that is the conversation worth having before anything is commissioned. Tell us the task and where your model is in its lifecycle, and we will help determine what to capture raw, what to label, and when to do each.